| 1. |
Re: Text fajlok leghatekonyabb tomoritese mivel? (mind) |
32 sor |
 (cikkei) (cikkei) |
| 2. |
uuencode (mind) |
21 sor |
 (cikkei) (cikkei) |
| 3. |
Ha mar tomorites (mind) |
17 sor |
 (cikkei) (cikkei) |
| 4. |
uuencode vs base64 (mind) |
25 sor |
 (cikkei) (cikkei) |
|
| + - | Re: Text fajlok leghatekonyabb tomoritese mivel? (mind) |
VÁLASZ |
Feladó:  (cikkei) (cikkei)
|
Sziasztok!
: hello.bz2 nálam 397 byte lett bzip2 maximális tömörítéssel és
: szerintem bármely tömörítő letömörítené hasonlóan picire
Persze. De a hello<sortores>1000000 meg igy ASCII karakterekkel is csak
14 byte, tehat a "minimalis" eredmenyhez kepest 28-szoros meretet
tud a bzip2. Es ez igazabol meg nem minimalis. Az egymilliot irhatnam
1e6 alakban, ami tovabbi 4 byte-ot sporol.
Ha vesszuk, hogy csak kisbetu van benne, akkor eleg a 26 angol
karakter + sortores. Ez lekodolhato 5 bittel es meg marad egy karakter
a soremelesre es arra, hogy vege a szovegnek es az ismetlesek szama
kovetkezik. Az egymillio binarisan lekodolhato 20 bittel, tehat a
hello<sortores><ismetlodesi szam jon>1000000 az uj algoritmussal
7 karakter * 5 bit + 20 bit = 55 bit. Ezt vesd ossze most a
397 byte-tal. Es ebben a 7 byte-ban meg mindig van redundancia, mert
az 5 bites karakterekbol a 32 lehetseges karakter helyett csak 6-ot
hasznalunk, tehat eleg lenne 3 bit/karakter is (amiben meg mindig
van redundancia), tehat 41 bit is eleg lenne, vagyis a bzip2 77-szeres
meretet produkal.
A problema itt persze az, hogy a tomoritesi algoritmus mar nem univerzalis,
egy csomo informacio mar az algoritmusban van es nem a tomoritett
eredmenyben. Erre irtam, hogy a celfajlra kihegyett algoritmus es
parameter kombinacio az optimalis. Hogy ezt mennyire eri meg megkeresni,
az teljesen mas lapra tartozik. Magyarul, nem csak a tomoritett fajlt kell
eltarolni, hanem a (ki)tomorito programot is, es a ketto meretenek osszeget
kellene minimalizalni informatikai szempontbol.
Udv,
marky
|
| + - | uuencode (mind) |
VÁLASZ |
Feladó:  (cikkei) (cikkei)
|
Sziasztok!
Az uuencode-nal nem volt feladat, hogy papirra kinyomtatva
valaki utana meg be tudja gepelni. A problema abbol adodott,
hogy az uucopy es az email eredetileg 7 bites karaktereket
tudott, a 8. bitet vagy tovabbitottak, vagy nem (ekkor a
tuloldalon ugye a 7->8 bit konverzional kinullaztak),
tetszes szerint es a kuldonek nem szoltak, hogy mit
csinalnak a 8. bittel. Lasd regi HIX-eket, amikor egyesek
"marpedig a magyar nyelvben ekezet van, amit en hasznalok"
alapon olvashatatlan karaktersorozatkent jelentek meg. Tehat
itt csak egy 8->7 bites atkodolasra volt szukseg.
Az EBCDIC az IBM nagygepek karakterkeszlete (en is csak
szobeszedbol ismerem).
A base64 a valtozatos karakterkeszletek/kodlapok/
adattovabbitasi rendszerek kozos nevezoje.
Udv,
marky
|
| + - | Ha mar tomorites (mind) |
VÁLASZ |
Feladó:  (cikkei) (cikkei)
|
Sziasztok!
Ha már ennyi szó esik a tömörítésről, hadd kérdezzek én is:
Szóval minap unalmamban elolvastam egy hosszú egyetemi jegyzetet info
kommunikáció témakörben, sok hablaty között (GDF-es jegyzetről van szó,
jó
pár éves, nem is csodálkoztam rajta :-O ), szóval azt olvastam benne, hogy
a vonalas telefonon folytatott beszélgetést is átkódolják Vocoderrel, mint
ahogy a mobiltelefon esetében történik, veszteséges tömörítéssel. Nem egyes
alközpontokról volt szó, azt tudom, hogy vannak ilyenek, hanem úgy
általánosságban, globálisan. És az jutott eszembe, hogy akkor pl. a modem,
a fax mégis hogyan működik? Avagy ezek erre eleve felkészültek? Vagy azért
nem hajlandó az 56K modem csak max 42-vel menni? Nem tudom, mert nagyon
régen modemeztem, lehet, hogy már nem is működne a mai vonalakon?
--
Török István ___
|
| + - | uuencode vs base64 (mind) |
VÁLASZ |
Feladó:  (cikkei) (cikkei)
|
Mindkettő 8 bites sorozatból csinál 6 bites sorozatot, azaz praktikusan
3 byte-ból 4-et (3*8 = 4*6).
A 6 bit az 2^6 = 64 jel.
A különbség annyi, hogy a uuencode és a base64 más 64 jelet választott:
uuencode
!"#$%&'()*+,-./0123456789: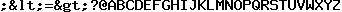 [\]^_
base64
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
A uuencode előnye, hogy a használt jelek pont így vannak sorban az ASCII
készletben, tehát emlékezni sem kell a sorrendre, csak a kezdőpontra.
A base64 előnye, hogy a betűkön és számokon kívül csak + és / van benne.
Ez azért fontos, mert pl. az EBCDIC-ben többek között nincsenek ezek a
karakterek: []\^
Tehát a uuencoded szöveget nem tudja átvinni.
Üdv,
Jozsi. [\]^_
base64
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
A uuencode előnye, hogy a használt jelek pont így vannak sorban az ASCII
készletben, tehát emlékezni sem kell a sorrendre, csak a kezdőpontra.
A base64 előnye, hogy a betűkön és számokon kívül csak + és / van benne.
Ez azért fontos, mert pl. az EBCDIC-ben többek között nincsenek ezek a
karakterek: []\^
Tehát a uuencoded szöveget nem tudja átvinni.
Üdv,
Jozsi.
|
|
